The Digitrail survey conducted by Sitra in December 2019 monitored the flow of individual data in digital services and investigated the opportunities for and ability of individuals to understand the operating environment of the data economy. Six test subjects were enlisted to carry out the study.
Sitra’s previous citizen survey indicated that the flow and use of data should be investigated. According to the survey, 43% of Finns considered that the lack of trust in service providers keeps them from using digital services. Some 71% of respondents wanted fair digital services to be identifiable.
How was the Digitrail survey conducted?
The test subjects were a 16-year-old upper secondary school student (boy), a middle-aged journalist (female), a middle-aged politician (female), a 22-year-old university student (female), a pensioner (female) and a middle-aged executive manager (male).
The main questions addressed by the survey were:
- How much data is accumulated about us, and for whom?
- What is our personal data used for?
- Is my data collected/used in accordance with the General Data Protection Regulation?
- What data is collected through me about others as well (my contacts)?
- What kind of trade is taking place with our data?
- How are we profiled/scored and what are the profiles/scores used for?
We only received partial answers to some of the questions (4 to 6), and none to some.
The Digitrail survey focused on the use of data related to marketing and advertising. Areas in which receiving and sharing data is purely beneficial to all of the parties and complies with the principles of openness and transparency were excluded from the survey.
Methods used in the survey
Analysis of network traffic data
- The mobile data traffic of the test subjects was stored for approximately two weeks.
- The test subjects were given Android test phones with preinstalled VPN and monitoring applications.
Comparison of the data protection documentation of select (14) companies
- The companies were chosen from among the digital services used by the test subjects.
- The companies’ privacy policies were examined to find out what data they collect and how accurately the companies explain the collection and use of data.
The same companies’ answers to questions pursuant to the General Data Protection Regulation
- The test subjects sent the companies they used a request pursuant to the General Data Protection Regulation to obtain a copy of their own data and more specific questions.
- The answers were used to find out what kind of data the services collect about the users and how they describe the third parties associated with the use of data and profiling.
The test subjects used their own SIM cards with the test phones. They also used their own phones alongside the test phone, some with another SIM card. The test subjects used their own phones for those services where they restricted data monitoring (such as work-related matters, banking services and health services).
People do not have a realistic opportunity to understand the complicated marketing networks of the data economy
The users of web services are not easily able to see what data is collected about them and which third parties the data is disclosed to. People have to trust the generalised and obscure cookie policies, privacy policies and terms of use of the services, prepared solely on the terms of the companies to protect their interests.
It is also impossible for the ordinary person to understand the amount of data collected and the role of the third parties. Many third parties also exchange the data they obtain. Moreover, some combine cookies with diverse identifiers (cookie syncing), comprising a holistic picture of a person, even if several devices are used.
“If the services were more transparent, it would increase trust.”
(22-year-old student)
Children are particularly vulnerable, as data collected about them is a commodity in the same way as that of adults, and they have practically no chance of understanding the obscure cookie descriptions on websites or the terms of use of diverse applications.
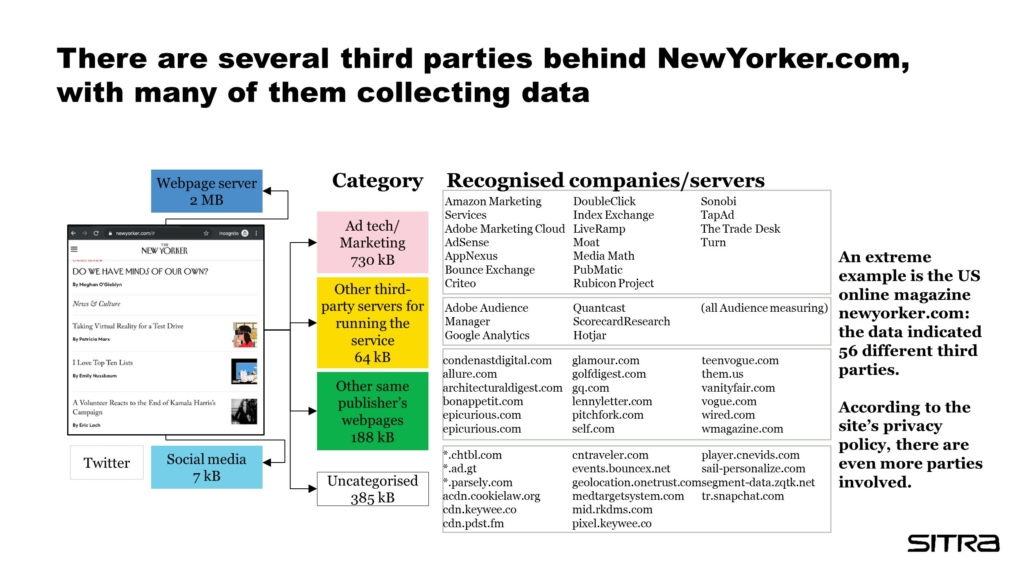
The Newyorker.com site, for example, turned out to have 56 parties to whose servers the user’s browser connects. Some of the parties are only there to ensure the functionality of the service or to develop it better based on visits, while some (in the figure, 18 AdTech/Marketing parties) collect data for enriching and reselling as a commodity for marketing and advertising purposes.
The flow of data is also illustrated by a Princeton University study (Online tracking PDF 01.2016) simulating 90 million visits to a million sites and investigating the number of third parties.
“I thought that my data remained with the service provider.”
(Journalist)
The Princeton University study shows that news sites have the highest number of third parties, while the sites of universities, NGOs, healthcare providers, the EU and governments have the least third parties. Of the third parties, the majority is owned by a few platform giants, meaning that a very high share of the data is obtained by a handful of companies (such as Google, Facebook, Twitter and AppNexus), even though the number of third parties is considerably higher.
Watch a real-life example how data is collected
Data in exchange for free games
With regard to games, being free of charge is important, especially for children and young people. One should understand that the gamer pays with their data, so gaming is not completely free of charge. Even if the user played only a single game (such as Subway Surfers), there is a large number of third parties in the background. The third parties are classified by task. The data indicated a total of 10 third parties (such as Flurry Analytics, Moat and TapJoy). Seven of these were in the advertising category.
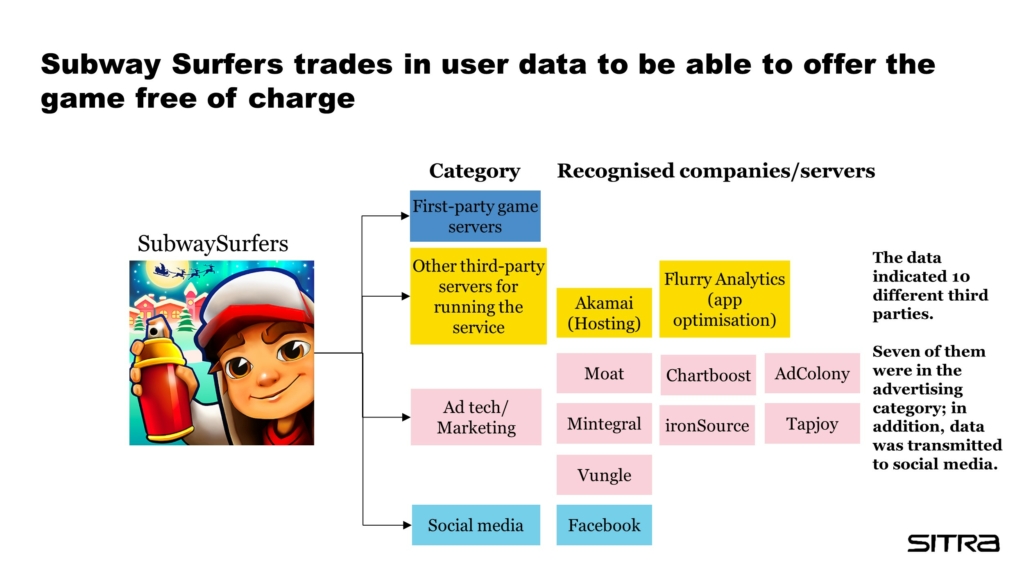
Flurry Analytics is an analytics service whose purpose is said to be to optimise applications. By looking at its website, it is not easy to understand what data it uses and how the data is combined. In addition, the link to the privacy policy links to Verizon Media’s privacy policy. Verizon Media is part of the gigantic Verizon Communications corporation that owns Yahoo, among others. The linked privacy policy does not specify the data used by Flurry Analytics, and it reports that data is shared between Verizon media and “trusted partners”.
Moat analyses the impact of advertising and how and where advertisements have been displayed (attention analytics). It is part of Oracle Cloud. Oracle’s privacy policy contains a lot of links, and it is not easy to find information about how Moat’s data is used from it.
TapJoy is a service associated with advertising sales. The collected traffic data reveals that it uses a device- and user-specific identifier (tracking ID). This makes it possible for TapJoy to combine data from different services.
“It was not a surprise that my data is disclosed to different places, but the number of third parties surprised me.”
(16-year-old upper secondary school student)
Advertising-related parties collect data from several sources. A total of 37 marketing-related third parties were identified in one test subject’s data. They collected data from a total of 22 sites or applications. The domiciles of the third parties were the EU (9 parties), the USA (27) and Canada (1).

The data of the Garmin well-being application did not indicate third parties. The result is in line with the privacy policy. The policy only mentions two third parties, associated with payments and logistics. This is typical of services whose business model is exclusively based on collecting data through their own application. It is important to the company from the point of view of enhancing the product, developing new products and committing customers.
The General Data Protection Regulation works only partly
It is impossible for the user to obtain a comprehensive overview of their data: the amount of data that is accumulated about them, how it was collected, who processes and refines it, and how the collected data is used in general. Because the data is incomplete, it is also difficult for people to find out if the profiling has been made based on accurate data.
“You need an expert to describe in plain language that this is a world where data starts moving around. You cannot understand it by yourself.” (Journalist)
Due to the complex network of data collectors and users, the General Data Protection Regulation works only partly. People may have learned from the GDPR about asking about the use of their data from primary service providers. However, because of the multi-layered data sharing network, people might not know the third parties to which their data is also disclosed. People have the right to request their data from the third parties, but it has been made extremely difficult to actually exercise that right.
There is a systemic problem with the data economy: business models
With the digital advertising environment, which is a significant area of the data economy, being so complicated, it is impossible even for experts in the field to fully understand how it operates. There is an extensive network of unknown parties behind individual services, with no direct connection to the users of the users.
The individual’s point of view
The business models of digital marketing are, as a rule, detrimental to privacy. The reason for this is that the targeting of advertising has been based on the maximum number of characteristics, regardless of their importance.
Data disclosed by people themselves, such as an email address, interests or name, are not sufficient for the current digital advertising business models; there is a will to store all data relating to online behaviour. The data is comprised of likes, page visits, browsing, gaming, people’s contacts or use of search engines, among other things.
“The worst threat is that data is used for political manipulation.” (22-year-old student)
The data is used for creating as many data products as possible about people, as comprehensively as possible. It is a known fact that it is impossible for an individual person to cope with all different cookie policies and privacy terms, as it would simply take too much time and render the use of the internet senseless.
Companies’ point of view
European companies have invested enormous amounts of resources into complying with the General Data Protection Regulation, and in large corporations in particular, the projects have often been extensive and expensive. It could be said that while companies located in the EU have invested significantly in enforcing the General Data Protection Regulation, there is a number of international data economy companies whose operations remain in the dark with regard to the GDPR.
Years of problems caused by digital marketing and advertising with regard to privacy have attracted the interest of consumers, companies and the authorities. Business models built around personal data often cannot stand the light of day, and marketing professionals, for example, have begun to question the functionality of audiences profiled with excess precision. The methods of marketing and advertising are currently being re-evaluated, and the industry is undergoing a significant change that it has initiated itself. There has also been a considerable amount of fraud affecting advertisers, with bots clicking on advertisements. As a result, advertisers have been paying for nothing.
It is also problematic that data is collected into digital advertising silos so that it is difficult for other companies to learn about their customers and thereby difficult for them to develop new services and products that interest customers. From the point of view of ordinary companies, it is beginning to look like the conventional ways of accumulating in-house customer data capabilities will experience a revival.
Next steps
The results of the Digitrail survey conducted in late 2019 are still being analysed, and a more detailed summary than this article will be published later in the spring.
The Digiprofile test launched by Sitra in January 2020 helps users to understand the operating principles of the data economy and provides tips about protecting their own data.
Sitra’s work to promote a fair data economy Fair data economy The part of the economy that focuses on creating services and data-based products in an ethical manner. Fairness means that the rights of individuals are protected and the needs of all stakeholders are taken into account in a data economy. Open term page Fair data economy will continue. The General Data Protection Regulation has afforded some transparency to the movement of data, but Sitra’s IHAN project aims to pave the way for a fair data economy for everyone.

How can you protect your data?
Instructions for protecting data are available on several websites:
- Sitra’s Digiprofile test (in Finnish, Swedish, English)
- Your Online Choices
- Data Ethics
Survey parties
The survey was conducted by Sitra and Futurice. The co-operation also involved Paul-Olivier Dehaye, the founder of PersonalData.IO.
Sources
The following materials were also used in the survey:
- THE GREAT DATA RACE How commercial utilisation of personal data challenges privacy. Report, November 2015
- Princeton University: Online Tracking (PDF): a 1-million-site Measurement and Analysis, 2016
- OUT OF CONTROL How consumers are exploited by the online advertising industry, 2020
- WORLD ECONOMIC FORUM article, January 2020
#IHAN
Article edited on 28 April 2020: “Where’s My Data” -video added







Latest
Read more.